В этой статье рассмотрим ключевые походы к изменению значений в ячейках датафрейма Pandas - наиболее популярного формата первичной обработки данных для любителей Python. Оценку способов будем производить исходя из их результативности, скорости и трудозатратности.
Рассмотрим вопрос на примере конкретной задачи. Пусть имеется датафрейм, содержащий предсказания для пары object, item (например, размер поставки в филиал организации/object определенного материала/item) следующего вида:
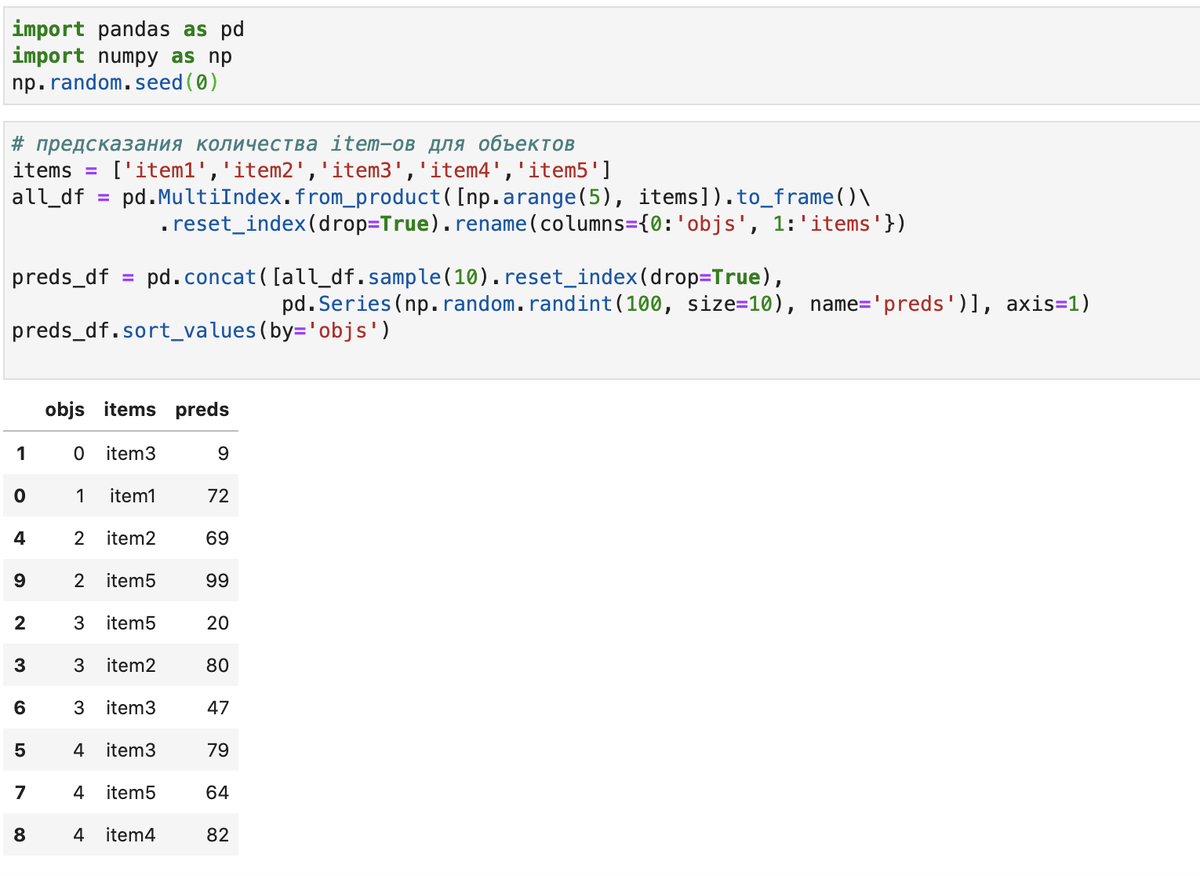
Для генерации набора сначала с помощью функции from_product объекта MultiIndex получили декартово произведение item-ов и объектов, а потом выбрали из них 10 случайных с помощью метода sample объекта DataFrame.
Нашей задачей является замена item-ов в датафрейме предсказаний при условии, что он отсутствует в некотором перечне возможных item-ов для объекта (задаем в obj_items_df, допустим, в филиале организации уже не используются гелевые ручки, а только шариковые). При этом правила замены одного item-а на другой (задаются в словаре maps_d):
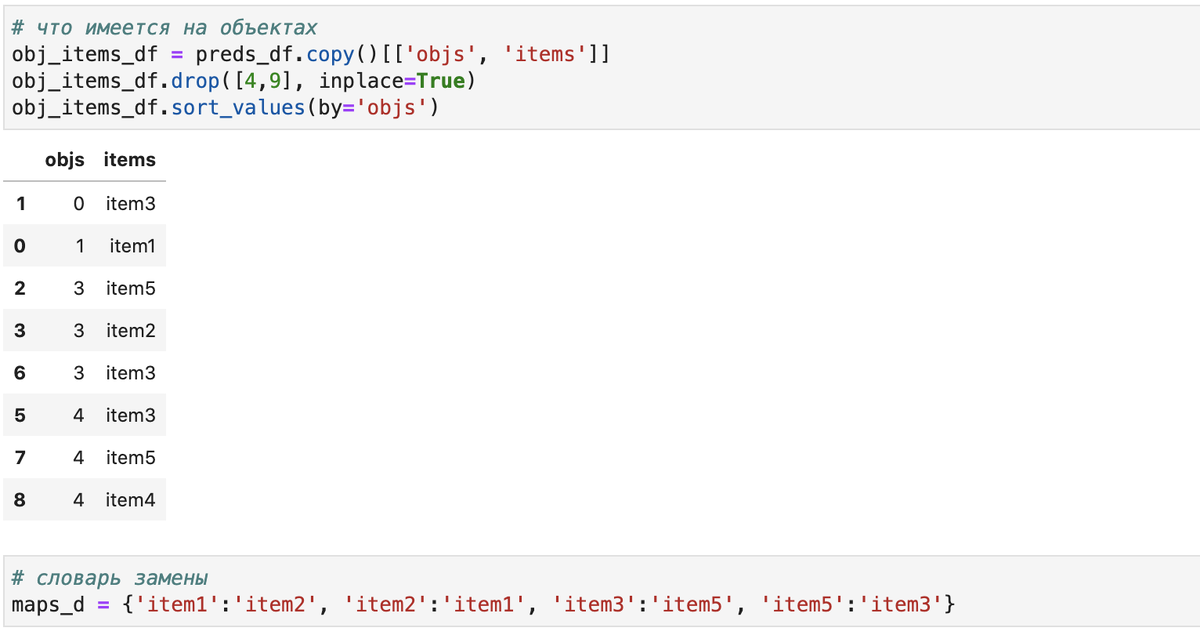
Как видно, в демонстрационных целях мы сформировали obj_items_df из значений самих предсказаний за вычетом двух строк (они и будут заменены).
Рассмотрим теперь несколько подходов для решения задачи:
- Задаем цикл по матрице предсказаний и в строках, где пара объект, item не попадает в список пар из obj_items_df осуществляем замену.
- То же, но сравнение присутствия объект, item происходит методом прихотливой индексации на уровне датафреймов.
- Оба датафрейма индексируются парами объект, item и операции наличия значений осуществляются на уровне индексов.
Преимуществом первых двух подходов является простота реализации:
Видим, что строки, где objs ==2 имеют item_new отличающийся от item в соответствии с нашим правилом. Обратите внимание, что при попытке внесения изменений путем выбора сначала строки i, а потом столбца item_new Pandas вернет предупреждение и не даст внести изменения:
Теперь проверим скорость метода:
Второй метод также выдает правильный результат:
но работает значительно медленнее:
А теперь перейдем к третьему способу. Он немного сложнее предыдущих, так как требует работы на уровне индексов. На основе обоих датафреймов (preds_df, obj_items_df) создаются структуры с индексами из пар объект, item (preds_ser, obj_items_flag), затем вызывается переиндексация obj_items_flag и flag для новых значений становится равным null, что инициирует правило замены. Код представлен ниже:
На заданных данных несмотря на трудоемкость время метода не очень впечатляет:
Если же увеличить объем данных, то соотношение скорости сильно поменяется:
Вывод - логику многочисленных операций сравнения в датафреймах лучше реализовать на уровне индексов. А вы что бы добавили?



















