
Одной из наиболее муторных вещей при написании парсера/скрапера является реализация функции скачивания содержимого из заданных мест на странице. Процесс поиска последовательности тегов для перехода к интересуемой информации сталкивается с различными трудностями, одной из которых является дублирование тегов в разных местах веб-страницы.
Например, продолжим разбор страницы детализированной статистики поединков в рамках UFC, имеющей следующий вид:
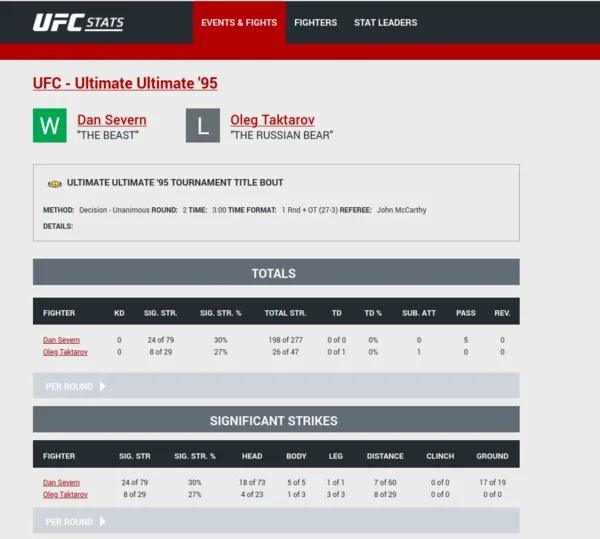
Ранее мы вывели информацию из верхней части этой страницы (смотри статью), теперь рассмотрим как выглядит нижняя половина:
То есть информация о нанесенных ударах общая, по каждому раунду, а также с разбивкой на области повреждения, находятся в тегах с одинаковым названием 'section' и с полем 'class'='b-fight-details__section js-fight-section'}. При этом они также содержат таблицы с одинаковыми названиями ячейками (тег th). Если мы последуем прежней стратегии поиска и, например, попытаемся получить содержание полей из сектора с заголовком "TOTALS" на картинке, то получим смесь полей (включая, например, названия из подтаблицы "SIGNIFICANT STRIKES")
delay = 1
url = 'http://www.ufcstats.com/fight-details/524b49a676498c6d'
html = net_scrape.get_url_delay(delay=delay, url = url).text
bsObj = BeautifulSoup(html, 'lxml')
total_res = bsObj.findAll('th',{'class':'b-fight-details__table-col'})
[item.get_text().strip() for item in total_res]
В этом случае лучше работать с участками страницы раздельно. Так, в нашем случае мы могли бы получить секции и загружать информацию из каждой по отдельности либо задать объемлющую таблицу для наших ячеек (если такой же другой нет, конечно). Для этого я написал небольшую функцию (реализована как метод класса), которая возвращает определенный набор тегов, содержащихся в некотором контейнере с заданными параметрами. На входе она принимает url или объект из библиотеки BeautifulSoup (страница или тег), а также словарь или строку с описанием тега контейнера - его имени, свойства (например, 'class') и значения, а также аналогичную информацию для описания содержимых тегов. Если вторым или третьим параметром передается строка, то нужно разделить все слова запятыми и она автоматически будет преобразована в словарь.
from bs4 import BeautifulSoup
from bs4.element import Tag
from general_modules import net_scrape
@classmethod
def get_items_list_from2tags(cls,url_bs4,tag_container,tag,delay):
tag_container = tag_container if isinstance(tag_container,dict)\
else {'name':tag_container.split(',')[0],\
'field':tag_container.split(',')[1],\
'value':tag_container.split(',')[2]}
tag=tag if isinstance(tag,dict) \
else {'name':tag.split(',')[0],\
'field':tag.split(',')[1],\
'value':tag.split(',')[2]}
tag_list =''
try:
if not isinstance(url_bs4,BeautifulSoup) and not isinstance(url_bs4,Tag):
html = net_scrape.get_url_delay(delay, url_bs4).text
bsObj = BeautifulSoup(html, 'lxml')
else: bsObj = url_bs4
tag_list = bsObj\
.find(tag_container['name'],{tag_container['field']:tag_container['value']})\
.find_all(tag['name'],{tag['field']:tag['value']})
finally:
if not tag_list:
print('поиск двух контейнеров прошел неудачно')
raise StopException
else: return tag_list
Если теперь поискать ту же информацию, но задав объемлющий контейнер при помощи нашей функции, то получим ожидаемый результат:
total_res = ItemsParser.get_items_list_from2tags(bsObj,'tr,class,b-fight-details__table-row', 'th,class,b-fight-details__table-col', delay)
[item.get_text().strip() for item in total_res]



















