Начнем поэтапную реализацию парсера на Python путем программирования его отдельных структурных элементов. При этом будем придерживаться ранее указанной схемы, которая имеет следующий вид:
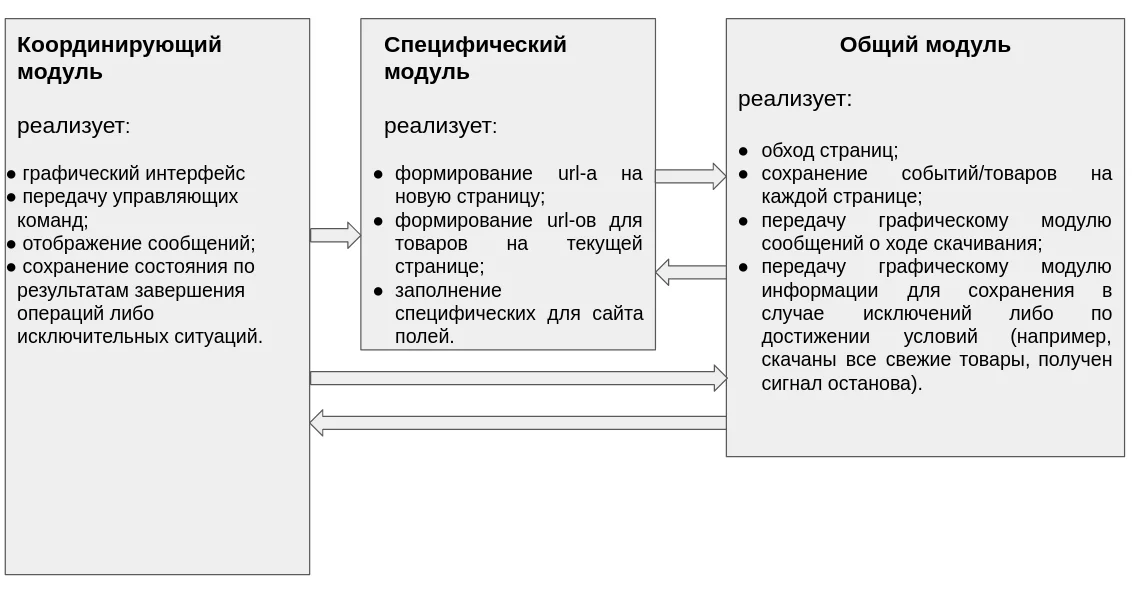
В данной статье реализуем функцию обхода и сохранения отдельных записей (например, спортивных мероприятий/характеристик продаваемых товаров), имея готовый список ссылок на них. Этот этап относится к "общему модулю" в предположении наличия функции обхода страниц и извлечения списка ссылок на события/товары на каждой из них (реализуем позже).
В целом функционал модулей будем реализовывать в Python классах, соответственно, поставленные задачи будут решаться в классе общего модуля ItemsParser, его методом get_items_params. В качестве явных параметров последняя принимает очередь сообщений (для диагностики работы программы) и время самой старой записи для скачивания (так как то, что раньше нас не интересует есть, например, уже скачано).
Данная функция обходит все ссылки на записи (все бои в рамках одного события либо товары на одной странице) и для каждой скачивает значения необходимых параметров (метод get_one_item_params) в словарь.
При этом метод get_items_params отображает количество пройденных и проигнорированных записей (если мы хотим остановиться по завершении скачивания только свежих записей, то показателем останова является прохождение заданного количества старых записей подряд, так как некоторые сайты могут за деньги поднимать несколько старых записей вверх). Таким образом, если новых записей больше не обнаруживается, функция выбрасывает исключение NoMoreNewRecordsException, которое обрабатывается в вышестоящей функции обхода страниц start_items_parser (о ней позже).
В get_items_params также предусмотрена остановка, если флаг паузы активен (это понадобится для принудительного прекращения операций из координирующего модуля, например, вы хотите выключить компьютер и вернуться к скачиванию позже).
Ниже представляю часть содержимого конструктора класса ItemsParser и код метода get_items_params.
class ItemsParser(metaclass=ABCMeta):
def __init__(self,cur_url, tag_container_el,tag_el, rec_ign_bef_stop_max = REC_IGN_BEF_STOP_MAX, pages_load_stop_num=PAGES_LOAD_STOP_NUM):
# url текущего события или страницы с товарами
self.cur_url = cur_url
# здесь будут храниться ссылки на записи (спортсобытия, товар)
self.items_hrefs = []
# переменная хранит собранные записи
self.items_list = []
# подсчет количества собранных записей за итерацию
self.records_pass_in_page_num = 0
# флаш, отслеживающий останов извне
self.pause_flag=False
# после стольки страниц скачивание
# останавливается автоматически
self.pages_load_stop_num = pages_load_stop_num
# иногда старые объявления поднимаются
# наверх, поэтому для критерия останова
# надо пройти несколько старых записей,
# чтобы убедиться, что новых нет
self.rec_ign_bef_stop_num = 0
self.rec_ign_bef_stop_max = rec_ign_bef_stop_max
Код функции get_items_params:
def get_items_params(self, items_hrefs, messages_queue = None, item_last_datetime=''):
start = self.records_pass_in_page_num
items_list = []
try:
for j in range(start, len(items_hrefs)):
if not self.pause_flag:
time1 = time.time()
url = items_hrefs[j]
# словарь со значениями одной записи
item_params = self.get_one_item_params(url)
# для проверки игнорируется ли текущая запись
records_ignore_was = self.rec_ign_bef_stop_num
if not item_last_datetime == '':
if item_params['date']<=item_last_datetime:
self.rec_ign_bef_stop_num = self.rec_ign_bef_stop_num+1
if messages_queue:
messages_queue.put('ignore {}'.format(self.rec_ign_bef_stop_num))
if self.rec_ign_bef_stop_num>self.rec_ign_bef_stop_max: raise NoMoreNewRecordsException
# если не надо игнорировать то добавляем
if records_ignore_was == self.rec_ign_bef_stop_num:
items_list.append(item_params)
self.records_pass_in_page_num += 1
if messages_queue:
time2 = time.time()
messages_queue.put('{} запись, ее обработка заняла {} секунд'.format(j,time2-time1))
else:
raise StopException
finally:
return items_list
Выделенна функция get_one_item_params будет отвечать за скачивание необходимых параметров записи в словарь. При этом поля будут заполняться в зависимости от специфики сайта из соответствующих тегов (как я рассказывал ранее) путем просмотра исходного кода элементов :