Возникали ли у вас когда-нибудь сомнения в родстве русского языка и украинского? А русского и белорусского? Вряд ли. Мы соседи, живём плечом к плечу больше тысячи лет. Тесно контактируем, и бывает иногда чрезвычайно трудно отличить по говору, кто перед тобой, выходец из Донецка, Ростова-на-Дону, Витебска или далёкой деревушки под Смоленском.
Украинский и польский, болгарский и сербский, словацкий и чешский, белорусский и хорватский — все мы одна большая, близкородственная семья. Как лингвистически, так и этнически (жаль, конечно, что не всегда политически...) Но что если я поставлю в такую же пару, скажем, русский и литовский? А русский и греческий? А русский и хинди? Последнее так вообще на грани абсурда!
Мысленно вижу, как уверенность в ваших глазах медленно угасает. А ведь зря, ой как зря! И этот пост я посвящу тому, чтобы вас в этом убедить. Как я буду это делать? Сейчас увидите. Тот, кто меня не любит — вы просто мне завидуете! Простите, не удержался :) Давайте к делу.
Geek-минутка
Прежде всего совсем чуть-чуть теории — чтобы всё последующее не казалось вам совсем уж чернокнижием.
Языковое родство изучает специальная наука — сравнительно-историческая лингвистика, или компаративистика. Науке этой около пяти сотен лет. Первые труды, посвящённые поиску языков-родственников, появились еще в середине 16 века, а настоящий расцвет компаративистики наступил в эпоху романтизма — в конце 18 — начале 19 века. Тут-то и возникли имена Франца Боппа, Вильгельма фон Гумбольдта, Расмуса Раска и других мыслителей, одержимых идеей существования в далёком-далёком прошлом языка-прародителя современных им европейских языков, а также мёртвых латыни, древнегерманского, древнегреческого и санскрита (древнеиндийского).
Среди них были и сказочники Вильгельм и Якоб Гриммы. В России же одним из первопроходцев сравнительной лингвистики стал Александр Христофорович Востоков. Вот в чём была их позиция.
Тысячи лет назад существовал индоевропейский праязык, на котором говорили древние люди, населявшие территории от Гибралтара вплоть до долин Инда и Ганга. Телевизоров и интернета тогда не было, и естественно, что люди, жившие на таком расстоянии друг от друга, не могли говорить везде одинаково, сохраняя свой праязык в первозданной форме.
Разность климата, ландшафтов, мировоззрения, жизненного уклада, а также соседство и контакты с другими народами неизбежно привели к насыщению праязыка различными, совершенно не свойственными ему элементами. Это привело к распаду индоевропейского праязыка сначала на макродиалекты, затем на диалекты, субдиалекты и так далее, пока от первозданного языка остались лишь едва заметные следы.
В конце концов пути развития каждого субдиалекта индоевропейского языка разошлись настолько, что представители некогда единого большого этноса совсем перестали понимать друг друга. А там, где нет общности языка, быта, условий проживания и истории, нет и общности этнической. Народы разделились.
Буквоеды правят миром
Изучая древние тексты, компаративисты начали натыкаться в разных языках на подозрительные соответствия, которые при ближайшем рассмотрении вырастали в целые ряды последовательных (и не очень) закономерностей. Изучив и систематизировав их, они поняли, что с их помощью можно с разной долей уверенности сказать, как бы выглядело то или иное слово в разных мёртвых языках, даже если такое слово не встретилось им нигде в письменных источниках.
И учёные подумали: а что если мы применим этот метод для воссоздания облика праязыка? Так возникло понятие праформы — гипотетического исходника, который с течением времени и под влиянием разных закономерных процессов деформировался, порождая примерно одинаковые слова в разных родственных языках. Изменяться могло не только произношение этого исходника, но и его значение — иногда даже на прямо противоположное. Но не беда: чем сильнее расхождения, говорили учёные, тем древнее слова, с которыми мы имеем дело.
Увлеклись этим делом настолько сильно, что за пару столетий были изданы сотни (если не тысячи) различных трудов, сравнивавшие между собой те или иные языки и искавшие общие корни между различными народами. Одной из вершин отчественного языкознания в этом направлении считается двухтомник Т.В. Гамкрелидзе и В.В. Иванова под названием «Индоевропейский язык и индоевропейцы», в котором впервые была реконструирована и представлена целостная звуковая и лексическая системы предполагаемого индоевропейского праязыка.
Как они это делали
Поиск языковых соответствий — это как расшифровка молекулы ДНК. Работа долгая и кропотливая. Действительно, по аналогии с анализом ДНК для установления родства между двумя людьми, лингвисты-компаративисты берут два или несколько отдельно взятых языков и выстраивают из них симметричные «ДНК-цепочки»: звук к звуку, звукосочетание к сочетанию, слово к слову, значение к значению. Чем больше процент выявленных совпадений, тем сильнее степень родства. Всё как у людей.
Но, как и в случае с ДНК, редкий исследователь-компаративист «размотал» больше 10-15 процентов от одной языковой молекулы. И дело здесь не столько в технических сложностях, сколько в отсутствии недостающих данных и невозможности их добыть. Посудите сами: древних письменных памятников, на которые можно опереться, довольно мало. Далеко не все они на 100 или хотя бы на 50 процентов читабельны, а круг тем, которые они затрагивают, как правило, весьма далёк от жизни современного человека. Всё это порядком затрудняет реконструкцию.
К тому же за несколько тысяч лет непрерывного бытия сегодняшние языки, как и современные народы, вступили в такое огромное количество беспорядочных связей друг с другом, что от исходного предка в них практически ничего не осталось. Яркий тому пример — язык хинди, который испытал на себе влияние такого количества других языков и диалектов, что нам и не снилось. В одной только современной Индии на моменте живут носители 447 различных языков и 2 тысяч диалектов. А если приплюсовать к этому всю её 5-тысячелетнюю историю?.. Даже не представляю, что нужно, чтобы свести здесь все концы с концами.
И всё-таки, что там было с экспресс-тестом?..
Несмотря на все тяготы и лишения, экспресс-тест на лингвистическую ДНК все же возможен. И проведу я его для вас прямо сейчас — чтобы всё-таки доказать заявленное в самом начале родство русского языка с литовским, греческим и хинди.
На самом деле сегодня эта процедура доступна абсолютно любому человеку с гугл-переводчиком в телефоне — не нужно иметь для этого специальное образование или квалификацию. Достаточно лишь знать, где именно разматывать наши молекулы.
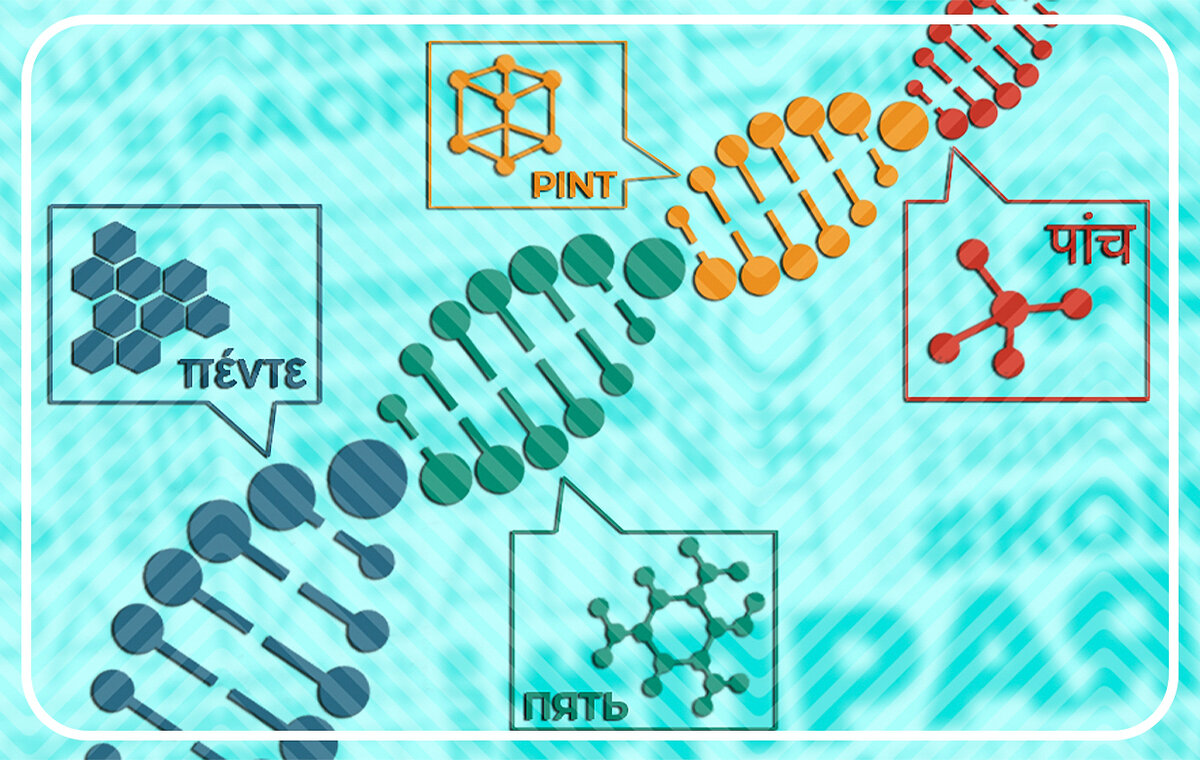
Итак, в фокусе нашего внимания будут названия чисел, терминов родства, сезонов и времён года, предметов быта и орудий труда, явлений природы и домашних животных. Это одни из немногих дошедших до нас групп слов, которые появились ещё во времена индоевропейской общности. Вот что получится, если выстроить цепь из случайных соответствий:
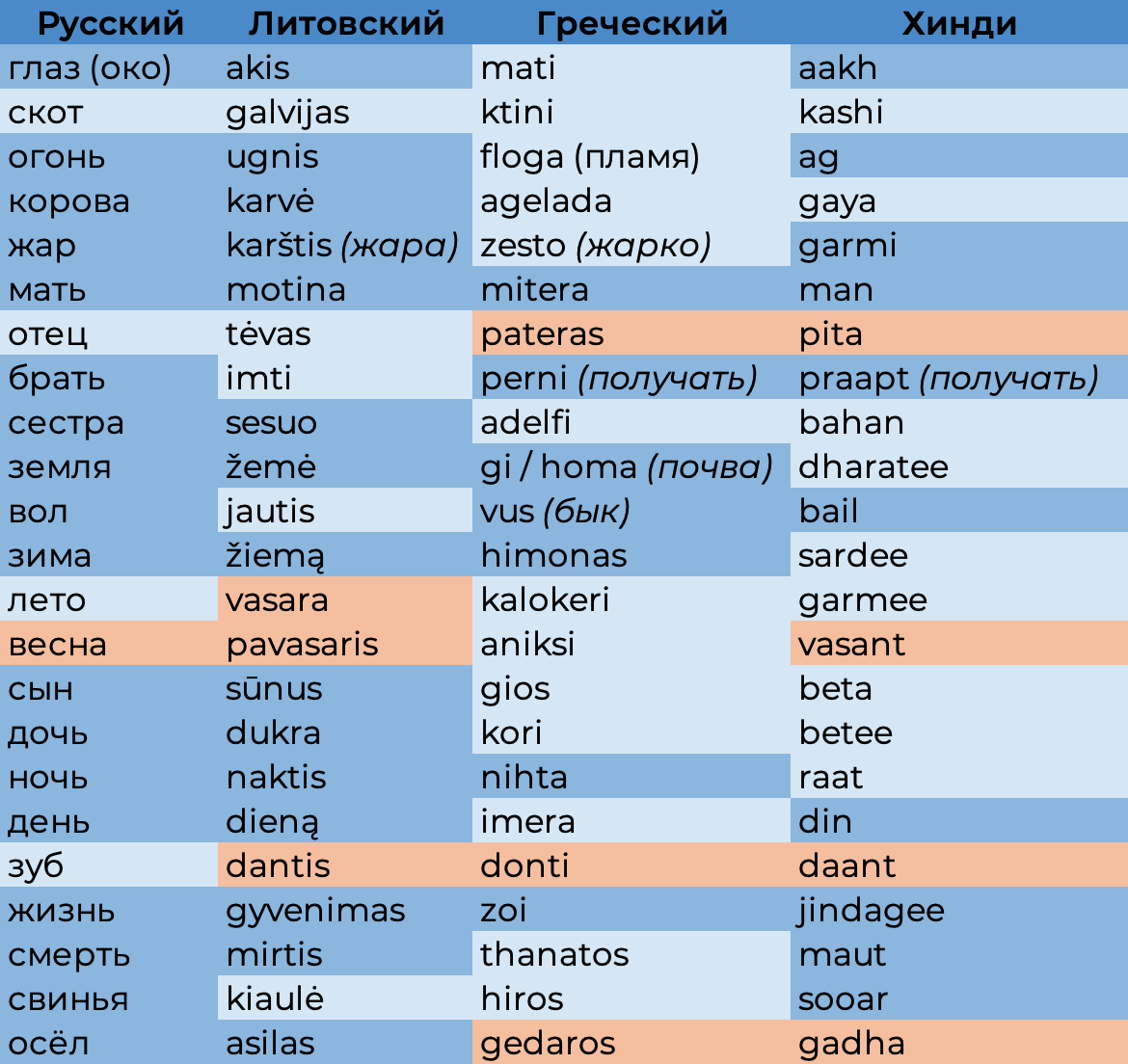
Результат, признаться, поражает. Из 23 параллелей явное генетическое родство с русскими словами (с поправкой на фонетические процессы, конечно) выявились в 17 литовских словах, восьми греческих и 12 словах на хинди! При этом греческий pateras и индийский pita, несмотря на несовпадение с русским «отцом» (как и литовское imti, что по-русски не «брать», а «иметь»), всё же имеют параллель в русском — всем известного «папу». А «зуб» по-литовски, по-гречески и на хинди, хоть и не совпал с «зубом» русским, но обнаружил связь с «зубом» итальянским (dente), французским (dent), латинским (dens/dentis) и другими европейскими.
Интересно и то, что литовская весна-vasara на самом деле «лето», а собственно «весна» — нечто вроде пред-лета (pavasaris). Это тот самый пример изменения не только звучания, но и значения, о котором говорилось выше. Зато литовский «осёл» оказался родным русскому, в то время как греческий, несмотря на колоссальные расстояния между ними и чрезвычайно разный бэкграунд, удивил своим родством с индийским.
Не убедил? Хорошо. В ход идёт тяжелая артиллерия — сравнение числительных от 1 до 10. Тут уж никаких сомнений остаться не должно:
В этом случае подкачали разве что «один», «восемь» (особенно литовское) и «девять». Не вполне прозрачно и родство «семёрок», но что касается «двух», «трёх», «пяти» и «десяти», то здесь, как любят шутить сами исследователи, различия практически нулевые.
(Замечу, кстати, на полях, что с «одним» тоже не всё так уж и однозначно. Если всё-таки принять во внимание, что предок древнерусского ОДИНЪ — праславянский *od-inъ — слово из двух корней. Отголоски второго из них — *inъ — как раз и видны если не в трех, то хотя бы в двух представленных параллелях. А ещё от него происходит современное слово «иной».)
***
Так что родню надо знать в лицо! Даже если это не всегда очевидно, даже если мы не всегда её понимаем...
Но впереди у нас ещё много лингвистических загадок прошлого. Вот увидите: разгадка каждой из них всякий раз станет новым шагом на пути к осознанию, что всё эта история с родством далеко — и совсем даже — не пустой звук.