Мне всегда было любопытно докопаться до сути и понять, как происходят те или иные процессы. И я докапывался. Думаю, что многим тоже этого хочется. Поэтому и пишу свои статьи в помощь таким любопытным. И сегодня о том, как происходит обмен данными между браузером и серверами в Интернете.
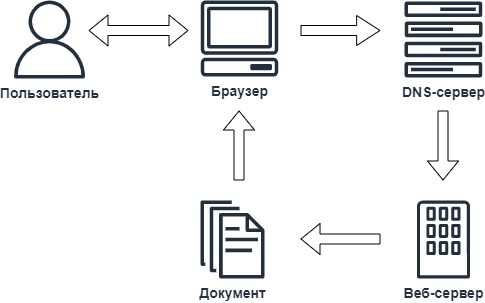
Движение начинается на стороне клиента (пользователя), когда пользователь запускает браузер на своём компьютере. Браузер обычно отображает какую-то домашнюю страницу, которая может храниться не обязательно в Интернете, но и на локальной машине (на вашем компьютере).
Выходя в сеть, браузер сначала обращается к Серверу Доменных Имён (DNS - Domain Name System, но это не российский магазин техники))), чтобы преобразовать имя сервера, на котором хранится запрашиваемая страница, в IP-адрес, перед тем как послать запрос другому серверу через Интернет. Этот запрос, также как и возвращаемый ответ, создаётся по определённым правилам, которые описаны в стандарте Протокола Передачи ГиперТекста (HyperText Transfer Protocol - HTTP).
Кстати, именно поэтому в адресе страницы в самом начале есть буквы http, например, http://asu-app.ru/. Это означает, что обмен данными должен выполняться по протоколу HTTP. Ну и, как вы догадались, могут быть и другие протоколы, то есть правила обмена данными. Например, FTP.
Большую часть времени сервер проводит в прослушивании сети, ожидая предназначенные ему сообщения (то есть запросы, в которых содержится его уникальный адрес).
Получив такой запрос, сервер выясняет, имеет ли обращающаяся к серверу сторона право на получение запрашиваемого документа. Если да, то сервер проверяет наличие у себя запрашиваемого документа. Если документ существует и доступен, то сервер отправляет его браузеру.
Сервер обычно сохраняет (регистрирует) данные запроса, куда входят IP-адрес компьютера клиента, запрошенный документ и время, когда произошло данное действие (время обычно по Гринвичу, либо это время сервера, но не время клиента). Кроме этого, сервер может приложить к документу дополнительные сведения с помощью cookies (куки), которые могут содержать дополнительные данные о браузере и его владельце.
Затем документ прибывает в браузер. Если браузер может отобразить содержимое документа, то он это делает. Если нет, то предлагает пользователю какие-то варианты действий (например, сохранить запрашиваемый документ на компьютере, либо установить дополнительное расширение для просмотра документа).
В большинстве же случаев браузер получает HTML-документы, которые содержат текст с символами разметки. Символы разметки браузер пользователю не показывает. И в итоге пользователь видит только содержимое с заданным оформлением. При необходимости браузер загружает другие элементы, например, картинки.
Пользователь читает документ. И, если, например, в документе есть гиперссылки, и пользователь щёлкает по такой ссылке, то он тем самым заставляет браузер передать новый HTTP-запрос и вышеописанный процесс начинается сначала.
Ну вот как-то так всё это и работает. Не забудьте поставить “нравку” и подписывайтесь на канал, чтобы ничего не пропустить…