Парсинг веб-страниц
Парсинг веб-страниц (scraping) нужен для многих целей: от борьбы с сервисами, которые не предоставляют API, до создания поисковых систем.
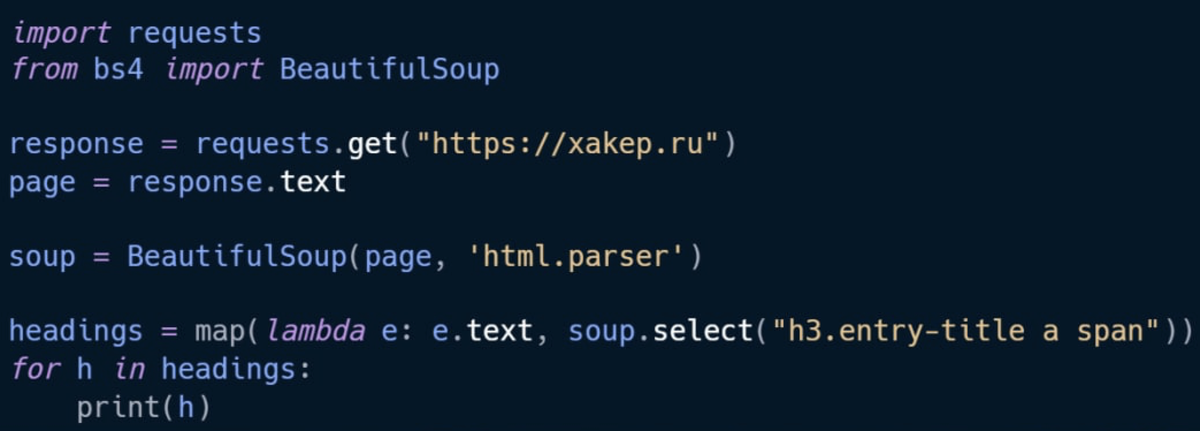
Для демонстрации мы извлечем заголовки новостей с главной страницы журнала. C помощью библиотеки requests и парсера HTML BeautifulSoup мы можем сделать это всего в несколько строк.
Установим библиотеки: pip3 install requests beautifulsoup4. Теперь откроем xakep.ru в отладчике браузера и увидим, что заголовки новостей находятся в тэгах <h3 class="entry-title">, но не напрямую, а во вложенных <a> и <span>. К счастью для нас, BeautifulSoup поддерживает селекторы CSS3, а в ее стандарте tag1 tag2 как раз означает «<tag2> вложенный в <tag1>. То есть, наш селектор для заголовков новостей будет h3.entry-title a span.
Сохрани в файл вроде xakep-headings.py и выполни python3 xakep-headings.py или просто скопируй в интерпретатор, и ты увидишь все свежие новости.