Всем привет, поговорим о кодировках. Кодировка - это описание символов числами (кодами), и будь она одна, не было бы и проблемы, какая разница, как там кодируются символы на экране. Но кодировок много. Есть предпосылки к тому, чтобы осталась одна, но пока приходится учитывать существование по крайней мере двух. И помнить про прочие.
Кодировки
Если речь про английский язык, то есть ASCII: семибитная кодировка, описывающая 128 символов. Туда входит латиница без диакритики, цифры и прочие символы стандартной клавиатуры и кое-какие управляющие символы. Однобайтная кодировка позволяет добавить еще столько же: туда можно поместить кириллицу или что-то еще, но но все сразу. Возникло множество кодировок на базе ASCII, из которых ныне можно еще встретиться с KOI8 и частенько - с кодировкой Windows (CP1251). Например, BiBTeX до сих пор работает с такой кодировкой, а не с юникодом, и это даже хорошо: позволяет правильно настроить соответствие строчная-заглавная и порядок букв в алфавите для сортировки.
Все сказанное уже, в основном, история, потому что сейчас повсеместно распространен юникод: многобайтная кодировка, в которой есть "всё" (даже Тенгвар Толкина). Их (юникодов) тоже много, но наиболее распространенная кодировка - UTF8. Ее особенность в переменной длине кода. Символы ASCII (7-битные) кодируются одним байтом и здесь полная совместимость с ASCII. Прочие символы кодируются двумя и более байтами, сейчас вроде как до четырех.
У юникода свои тонкости: так, символы с диакритикой могут иметь свой код (буквы й и ё ручаются за это), а могут быть представлены как базовый символ и диакритический знак. Но нас это не должно волновать, лишь бы был способ символ ввести, а уж Вим разберется, как его закодировать.
Пользователю Вим достаточно уметь открывать файлы в различных кодировках и сохранять их, при необходимости перекодируя.
Сразу скажу, что если в тексте есть символ, которого в кодировке (CP1251, например) нет (символ с диакритикой или какой-нибудь нестандартный, вроде тире, смайлика или интеграла), то Вим сохранить текст в этой кодировке не сможет. А найти неразрывный пробел не так просто. Но можно: /[a-z0-9 .,] в скобках надо перечислить всё, что есть на клавиатуре и в тексте.
Концы строк
Есть не менее двух стандартов обозначить конец строки. В Unix принят один символ с кодом, по-моему, 13. В DOS/Windows пара символов, номер 10 и номер 13. Был еще стандарт Mac, там только номер 10.
Это важно, потому что при переносе файла с одной системы на другую возможны сюрпризы. Код программы в одну строку - это забавно (хотя если код на Питоне, то может нервировать), а вот BiBTeX просто выдает ошибки, не распознавая их причину, и можно умом тронуться.
Вим умеет переключать концы строк и сохранять в любом формате.
Средства Вим
Переменная encoding описывает кодировку текста в буфере. Менять ее, скорее всего, не нужно. Но можно посмотреть: :set encoding
Вариантов очень много, делятся на три группы: 8-битные, 2-байтые и юникодные. Фактически по умолчанию utf-8 и на все случаи жизни должно хватить. Еще упомяну latin1, cp1251, koi8-r, ibm866, iso88595.
Переменная fileencoding (или fenc) задает кодировку файла, при записи текст будет перекодирован. На чтение эта переменная не влияет, о нем далее. Переменная своя для каждого буфера (файла), но есть глобальная, которую выставляет setglobal. Она используется для нового файла. Если пустая, то используется encoding, что и логично.
Переменная fileencodings задает список кодировок, и Вим при чтении файла будет пробовать их по очереди. Скорее всего, эту переменную менять не надо! Но если вдруг, то latin1 (и другие восьмибитные кодировки) надо ставить последней, так как Вим не может определить, что она не годится (он не пытается читать ваш текст). Специальное значение ucs-bom предписывает проверить, есть ли в файле меточка юникода (обычно в юникодном файле в начале она есть).
Переменная fileformat (или ff) задает стиль концов строк: dos, unix, mac. При чтении файла выставляется по факту. Есть переменная fileformats, которая указывает порядок, в котором надо пробовать.
Это все была теория: вряд ли вам надо менять эти переменные. Разве что fenc/ff можно задать перед записью файла, но и то: есть способ лучше.
Команды чтения и записи имеют параметры в форме ++xx=vv, и эти параметры локально отменяют действие переменных fenc, ff, binary и кое-что еще. Варианты:
- ++ff - отменяет действие fileformat, просто назначая стиль конца строки.
- ++enc - задает кодировку при чтении или записи.
- ++bin - выставляет флаг binary (без =),
- ++nobin - снимает этот флаг.
Например, :w ++ff=dos, ++enc=cp1251 mypaper.tex - и мы сохранили статью в кодировке Windows с концами строк в стиле Windows.
Еще есть ++bad, описывающая обработку невозможных для данной кодировки символов при чтении. Возможные значения:
- ++bad=?, где вместо знака вопроса может быть любой однобайтовый символ, предписывает заменять "плохой" символ на указанный.
- ++bad=keep - игнорировать плохие символы, и будь что будет. Небезопасно.
- ++bad=drop - пропускать "плохие" символы.
Команды, которые используют эти опции, это :w для записи, :e и :r для чтения, :tabnew для новой вкладки и другие.
Имейте в виду, что если в тексте затесался "плохой" символ, то Вим выдаст ошибку, и ++bad не поможет: при записи игнорируется. Ищите этот символ! Потому что даже если сумеете обойти и записать, проблемы потом все равно возникнут. Так часто бывает про копировании и вставке: вставили какого-нибудь Crème Brûlée в список литературы, и в cp1251 такое уже не влезет. В ТеХе есть для этого средства, но это предмет для отдельной беседы.
Меню
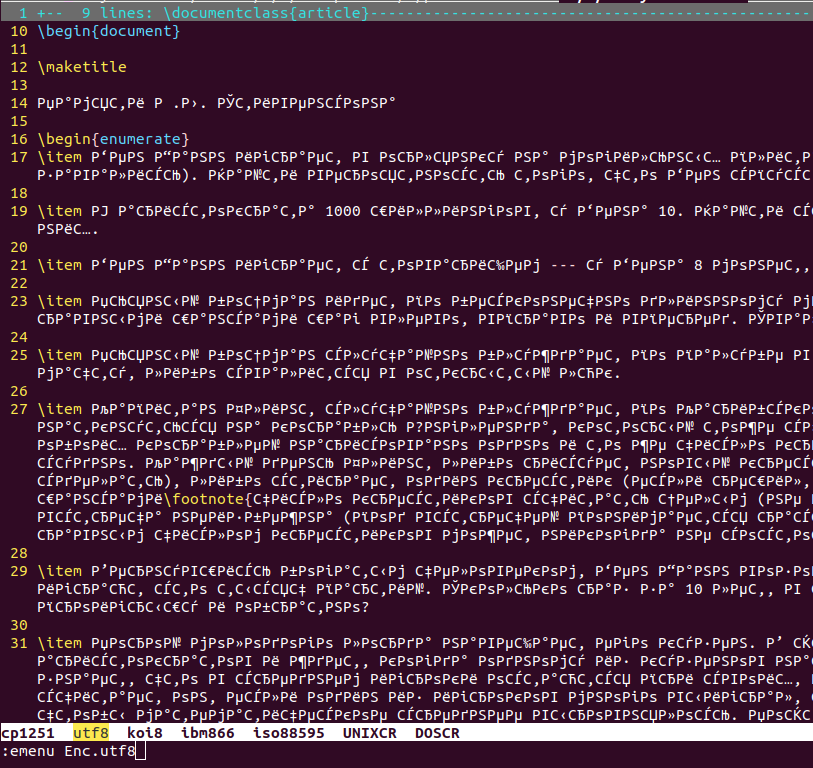
Удобно создать меню и занести туда все варианты. Например:
menu Enc.cp1251 :e ++enc=cp1251<CR>
menu Enc.utf8 :e ++enc=utf-8<CR>
menu Enc.koi8 :e ++enc=koi8-r<CR>
menu Enc.ibm866 :e ++enc=ibm866<CR>
menu Enc.iso88595 :e ++enc=iso-8859-5<CR>
menu Enc.UNIXCR :set fileformat=unix
menu Enc.DOSCR :set fileformat=dos
map <F8> :emenu Enc.<Tab>
map <F2> <Esc>:w<CR>
Такое меню открывается по F8 и позволяет выбрать кодировку (если открытый файл выглядит как на скриншоте) или конец строки. Потом можно сохранить файл уже в новой кодировке и с новыми концами строк обычной командой сохранения, которая повешена на F2.
Мне хватает и этого, но вы можете создать сколько угодно меню и пунктов в нем, и прозрачно сохранять и открывать файлы в любой кодировке.
Удачи, коллеги!



















