
В данной статье обсудим инструментарий обхода страниц в парсере/скрапере на Python. Напомню, что мы реализуем программу скачивания содержимого с сайтов, имеющих типичную структуру из набора страниц со ссылками на описания товаров либо произошедшие события (например, спортивные мероприятия). Общая схема парсера имеет следующий вид (подробнее здесь):
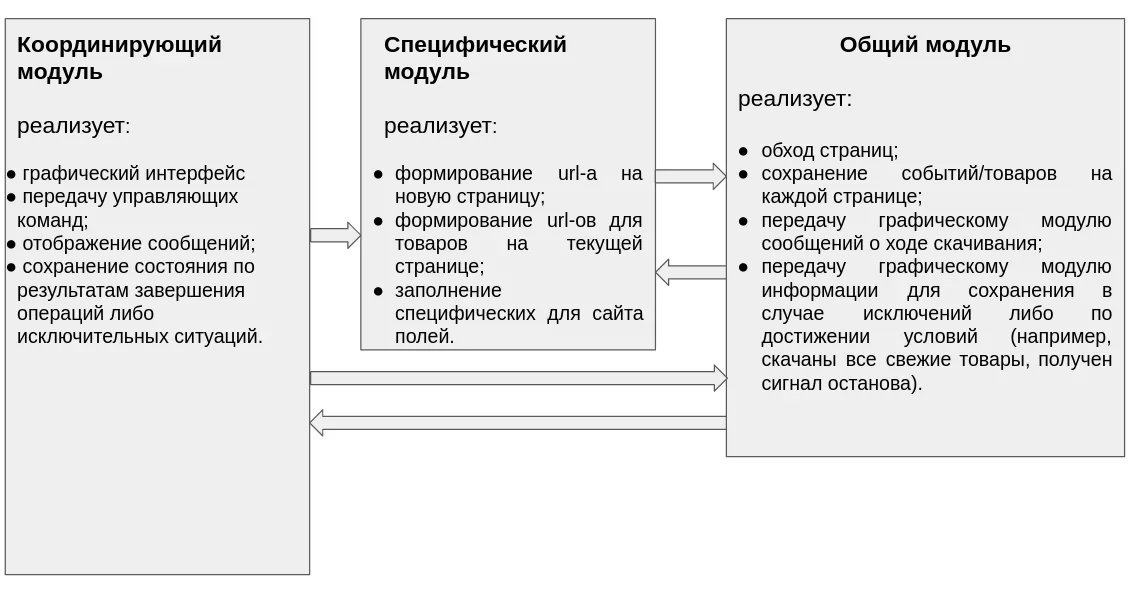
Ранее мы показали, как осуществлять обход ссылок на записи на одной странице (подробнее здесь) и сбор данных по каждой ссылке на примере конкретного сайта (подробнее здесь). Теперь напишем метод циклического обхода страниц и встроим в него уже реализованный функционал.
Ниже представляю код соответствующего метода обхода страниц start_items_parser класса ItemsParser и его конструктора:
class ItemsParser(metaclass=ABCMeta):
def __init__(self,cur_url, tag_container_el,tag_el, rec_ign_bef_stop_max = REC_IGN_BEF_STOP_MAX, pages_load_stop_num=PAGES_LOAD_STOP_NUM):
self.cur_url = cur_url
# строчные описания для тега контейнера ссылок и тегов,
# в которых непосредственно хранятся ссылки
self.tag_container_el = tag_container_el
self.tag_el=tag_el
# переменная хранит собранные записи
self.items_list = []
# подсчет количества собранных записей
self.records_pass_in_page_num = 0
# используется, если посылаем останов извне
self.pause_flag=False
# после стольки страниц скачивание
# останавливается автоматически
# сделано, чтобы много с одного ip не скачивать
# (а то заблокировать могут) и переключиться на другой
self.pages_load_stop_num = pages_load_stop_num
# иногда старые объявления поднимаются
# наверх, поэтому для критерия останова
# надо пройти несколько старых записей,
# чтобы убедиться в отсутствии новых
self.rec_ign_bef_stop_num = 0
self.rec_ign_bef_stop_max = rec_ign_bef_stop_max
def start_items_parser(self, messages_queue = None, item_last_datetime = ''):
i=0
time1 = time.time()
try:
# self.cur_url хранит адрес текущей страницы
while self.cur_url !='':
if not self.pause_flag and i <= int(self.pages_load_stop_num):
# получает ссылки на товары/события с текущей страницы,
# реализуется в специфическом модуле, так как
# зависит от конкретного сайта
items_hrefs = self.get_item_hrefs(self.cur_url,self.tag_container_el,self.tag_el, self.delay)
# собирает записи по полученным ссылкам, реализована ранее
items_list = self.get_items_params(items_hrefs, messages_queue, item_last_datetime)
self.items_list.extend(items_list)
if messages_queue:
time2 = time.time()
messages_queue.put('закончили итерацию по {} странице, ее обработка заняла {} секунд'\
.format(self.params[self.page_param], time2-time1))
# получение url новой страницы,
# реализуется в специфическом модуле
self.cur_url = self.get_next_url()
self.records_pass_in_page_num = 0
i = i + 1
else:
# после стольки страниц принудительный останов и смена ip
if i>int(self.pages_load_stop_num):
self.pause_flag = True
if messages_queue:
messages_queue.put('change ip')
raise StopException
# это исключение генерирует get_items_params,
# если новых записей нет
except NoMoreNewRecordsException:
if messages_queue:
messages_queue.put('no more new records')
finally:
pass
При этом get_items_params мы реализовали ранее (обход ссылок на записи на одной странице), а get_one_item_params, которая скачивает содержимое по заданной ссылке, возвращает словарь, объединяющий данные, полученные из каждого тега (подробнее здесь и здесь).
Для страницы с описанием одного поединка на http://www.ufcstats.com get_one_item_params можно задать в классе UFCFightsParser, наследующем ItemsParser, следующим образом:
class UFCFightsParser(ItemsParser):
---здесь конструктор, о котором расскжу позже
@classmethod
def get_head_details(cls, section, tag_container, tag_els, delay):
sec_head_t,_ = ItemsParser.get_items_list_from2tags(section,tag_container,tag_els, delay)
sec_head = [item.get_text().strip() for item in sec_head_t]
return sec_head
@classmethod
def get_fight_det_l(cls,tags_l):
res_l = []
for item in tags_l:
l = item.get_text().strip().split('\n')
res_l.append([item.strip() for i, item in enumerate(l) if i in[0,len(l)-1]])
return res_l
@classmethod
def fill_2fighters_stat(cls,fight_d,keys_l,body_l,round_num=''):
for i, key in enumerate(keys_l):
if i!=0:
fight_d[key+'_l'+round_num] = body_l[i][0]
fight_d[key+'_r'+round_num] = body_l[i][1]
def get_one_item_params(self, url):
html = net_scrape.get_url_delay(url = url, delay=self.delay).text
bsObj = BeautifulSoup(html, 'lxml')
# словарь с описанием всего события
fight_desc_d = OrderedDict()
# далее извлекается содержимое
# описанным ранее методом
event = bsObj.find('a',{'class':'b-link'}).get_text().strip()
fight_desc_d['Event'] = event
f_names_t = bsObj.findAll('h3',{'class':'b-fight-details__person-name'})
f_names = [tag.get_text().strip() for tag in f_names_t]
fight_desc_d['Fighter_left'] = f_names[0]
fight_desc_d['Fighter_right'] = f_names[1]
f_res_t = bsObj.findAll('i',{'class':'b-fight-details__person-status'})
f_res = [tag.get_text().strip() for tag in f_res_t]
fight_desc_d['Win_lose_left'] = f_res[0]
fight_desc_d['Win_lose_right'] = f_res[1]
f_det_res_t = bsObj.findAll('i',{'class':'b-fight-details__label'})
det_res = {}
for i,f_det_res_tag in enumerate(f_det_res_t):
key = f_det_res_tag.get_text().strip()
if not key=='Details:':
det_res[key] = f_det_res_tag.parent.get_text().strip().replace(key,'').strip()
else:
det_res[key] = f_det_res_tag.parent.parent.get_text().strip().replace(key,'').strip()
fight_desc_d.update(det_res)
sections = bsObj.findAll('section', {'class':'b-fight-details__section js-fight-section'})
sections = [sec for i, sec in enumerate(sections) if not i in [0,3] ]
sign_st_parent = bsObj.find('div',{'class':'b-fight-details'})
for child in sign_st_parent.children:
try:
if 'style' in child.attrs:
sign_st_table = child
except:
pass
sign_act_head = UFCFightsParser.get_head_details(sections[0],'thead,class,b-fight-details__table-head',\
'th,class,b-fight-details__table-col', self.delay)
sign_st_head = UFCFightsParser.get_head_details(sign_st_table,'thead,class,b-fight-details__table-head',\
'th,class,b-fight-details__table-col', self.delay)
sign_act_body_t,_ = ItemsParser.get_items_list_from2tags(sections[0],'tbody,class,b-fight-details__table-body',\
'td,class,b-fight-details__table-col', self.delay)
sign_act_body = UFCFightsParser.get_fight_det_l(sign_act_body_t)
sign_st_body_t,_ = ItemsParser.get_items_list_from2tags(sign_st_table,'tbody,class,b-fight-details__table-body',\
'td,class,b-fight-details__table-col', self.delay)
sign_st_body = UFCFightsParser.get_fight_det_l(sign_st_body_t)
UFCFightsParser.fill_2fighters_stat(fight_desc_d,sign_st_head, sign_st_body)
UFCFightsParser.fill_2fighters_stat(fight_desc_d,sign_act_head, sign_act_body)
for i, key in enumerate(sign_act_head):
if i!=0:
fight_desc_d[key+'_l'] = sign_act_body[i][0]
fight_desc_d[key+'_r'] = sign_act_body[i][1]
sign_act_rounds = []
rounds_body = sections[1].findAll('tr',{'class','b-fight-details__table-row'})
for i,sec in enumerate(rounds_body):
if (i!=0):
sign_act_rounds.append(UFCFightsParser.get_fight_det_l(sec.findAll('td',{'class':'b-fight-details__table-col'})))
for i,round_stat in enumerate(sign_act_rounds):
UFCFightsParser.fill_2fighters_stat(fight_desc_d,sign_act_head,round_stat,round_num=f'_{(i+1)}')
sign_st_rounds=[]
rounds_body = sections[2].findAll('tr',{'class','b-fight-details__table-row'})
for i,sec in enumerate(rounds_body):
if (i!=0):
sign_st_rounds.append(UFCFightsParser.get_fight_det_l(sec.findAll('td',{'class':'b-fight-details__table-col'})))
for i,round_stat in enumerate(sign_st_rounds):
UFCFightsParser.fill_2fighters_stat(fight_desc_d,sign_st_head,round_stat,round_num=f'_{(i+1)}')
return fight_desc_d



















